develop like the code is going to change, make sure it’s changeable, test it, refactor it, fail early, experiment and request feedback
deploy like it’s going to change, plan for scaling (even if you don’t have to), modularize, and automate whenever possible
create infrastructure like it’s going to change, adopt methods that let you pull out pieces and put in new ones.
Your setup is going to change, program like that’s the only thing that will remain constant.
On Testing
Testing is not about finding bugs. It’s not even really about making sure a piece of code works, you could do that yourself. Testing is to make sure you can change it later.
On projects
When you set up a project, if you have no built-in or prescribed way of specifying the dependencies of the project, you’re going to find yourself pulling your hair out down the road. You are going to have to wipe it out and start from scratch at one point, or even if you don’t, you still need to replicate the setup for stage, and production, and another developer. Save yourself some trouble, use the package management system or your language, or the one prescribed by the community. Setuptools for Python, npm for node, gem for ruby. Manage your own packages with these. It will save you mondo time down the road. If your language doesn’t have package management, bail, find a language that does.
and a rant
If you’re using Perl, use cpan minus, cpan is a pain, cpanm removes some of the pain. If you’re using php, well, god help you.
I want to write about the topic of learning, and how it pertains to my every day life in the workplace. I spent 18 months at my previous position, first by myself, and very quickly surrounded by a small team. We were working for a company that took great pride in being different, focused, and innovative. A company that made every effort to solve the needs of the client when noone else could or wanted to.
Learning as a necessity
I don’t think it’s disputed by anyone that learning is necessary to become adept at whatever your position is. It certainly was in mine. But it cannot stop there.
Learning is as necessary to development as water is to life.
It’s not enough to solve different problems in software development using the same patterns. It’s not enough to tickle the boundaries of your “programming comfort zone”. One of the demands of the position I was in at that time was to meet constant deadlines, and often overlapping ones. I’m quite proud to say I met all of them, and that the only thing that made that possible was continuous learning.
Continuous Learning
This is the kind of learning that means when you find a new technology that looks like it solves a problem that you have, you try it. You dive right in and find out if it’s going to do what it says it does. And then you do it again. You jump ship on frameworks. You jump ship on technology stacks, because each one has something different to offer.
Just as a problem can be solved in any language, so can a project be solved in any stack. It doesn’t matter what the stack is. What matters is that you learn it, because that makes you better.
Today it doesn’t matter that you know a language, or a framework. If you’re not good at learning, then you’re already losing the game.
Developer rot
There is such a thing in the software field as software rot, meaning if the environment is changing, and your software is not being updated to suit the environment, it starts to become a liability, and eventually rots and dies.
Similarly, a developer that has not taken the opportunity to be up-to-date with the current environment and culture (and I mean “software culture”) of the internet is suffering what I am coining today as “Developer Rot”.
A developer who is suffering developer rot is one who is trying to solve new problems using the same old tools. The tools work, but the environment is not the same. 12-month objectives are no longer feasible, 6 months is no longer an acceptible amount of time to put into a software project. Because we are learning creatures, and we do improve over time, we want to think we can write it faster and better this time around, and we really can! But the timeline for development within a given framework or toolchain is going to be fairly fixed. Boilerplate exists, component integration needs design, there are shiny new requirements for the project, and now your timeline is shorter. This is the reality of the entire evolution of my software career.
The real problem
“What problem does <insert new thing here> solve that I can do in <insert my language/framework here>?”
The problem of time.
If you spend (to pick a number) 20 hours to build a project using your current tools, and the new tool promises to cut your time in half, you have 10 hours now to learn that new tool. The gain beyond that becomes several- fold:
you’re learning new things
you’re becoming a better developer
you’re saving time
you’re giving more value to your clients
you’re supporting new technologies
you’re becoming a future advocate for these tools
you’re showing others how to do the same
You are also going to save that much time again on your next project, and you’re going to have fun. Excitement is a huge motivator, in fact, I would argue it’s the only real motivator.
The time is now
If you are saying, “those tools look nice, but I don’t have the time to learn them…” then you are already suffering from this condition. You will need to adopt and learn the tools as you encounter them, when they promise to solve your problems faster and better. And you need to continue to adopt. If you can solve a problem well in one language, you can solve it well in any language. If you can properly implement a project in one stack, you can implement it in any stack.
“But I’ll have 50 projects in 50 different software stacks…” Look at the internet: is it all written in Java? Can you even tell most of the time? Use good conventions to guide you and then dive in.
Netucation
“Real school” is starting to not mean much anymore. The new school is the internet. And the internet is changing. Every. Single. Day. Knowing a couple languages isn’t going to get you very far any more. Your best friend in the new web is the ability to learn. Don’t fight change, embrace it…
Today I ran across an interesting feature of Perl, as I was trying to test a variable key against a hash, essentially a key search. I’m still surprised at how accessible things are in Perl when I go to do something complicated, I find there is usually a very simple way to do it, clearly by design.
An Example
Searching against a set of keys in perl is quite simple, given the following hash:
For a bit of code that I’m working on, I need a little more complicated search though, I’m testing a dynamic string against the set of keys for a given hash, turns out the answer is equally simple:
Pretty straight forward. This example doesn’t really give a lot of power just yet, mostly because the regular expressions are over-simplified. It was in my next example that the nature of list and scalar context started to become clear to me in Perl. According to this page on the perldoc site, “[grep] returns the list value consisting of those elements for which the expression evaluated to true. In scalar context, returns the number of times the expression was true.”
This is neat. In the first example below, we get the match count, and the second, we get a list of matches from the same grep. The only difference is the context assignment, denoted by $ or @.
1 2 3 4 5 6 7
# get results in scalar context $moo = grep {/^b/} keys %foo; print $moo; # 3
# get results in list context @moo = grep {/^b/} keys %foo; print @moo; # batbarbiz
Scalar wut?
This article describes a scalar as the “most basic kind of variable in Perl… [they] hold both strings and numbers, and are remarkable in that strings and numbers are completely interchangable.” Maybe remarkable if you are coming from C, or a strict language where dynamic typing is not allowed.
A little deeper
A scalar turns out to be just a variable, but one that can only hold a single value. If you need more than one value, you need a list, and a lookup, you need a hash. Scalar variables in Perl can be a number, a string, even a reference to a more complicated type. In the the case of an array reference or a hash reference, you can think of the scalar variable as a pointer to the original object, which can be merrily passed around at will.
1 2 3 4
%hash = ('foo'=>'bar'); # my hash $ref = \%hash; # $ref is a hash reference
$obj->my_sub($ref); # pass the reference to a subroutine
This language is wierd. Larry Wall must have thought he build the best thing ever when he created Perl. If feels a lot like vim, except that you have about 6-10 possible ways to do any given command. TIMTOWTDI is a great mindset for a language in terms of flexibility, but as soon as you get into someone else’s code, you realize you don’t know anything about the language again.
I want to start off by saying that Perl has to be one of the most fantastic languages I’ve every had to work in. I’m not really learning it because I have a keen interest in Perl, I’m learning to be helpful regarding the legacy codebase at my work.
A little grind goes a long way…
I wrote a bit of a script, after spending a few weeks perusing through a hefty codebase, and even with a little bit of Programming Perl under my belt, I still don’t have the skill to just roll out a lot of code off the top of my head. To make sure I was putting some test coverage in place (of which there isn’t in this particular project), I looked up Test::Simple and Test::More and started the file that would house my tests.
I found after I have covered the existing code that I was looking at my new function stubs, and wondering how to best describe what they were going to do. Without even really thinking about it, I started writing tests to say, “It should do this, or that” and in a couple minutes I had created a spec for the function I was writing.
Almost like fun
The neat thing is, having the spec in place allowed me to play with the code a little bit to see if it was doing what I wanted when I tried different things. If you recall, Perl has that “There Is Moar Than One Way To Do It”(TM) thing, which can be a good and a bad thing, but more about that later.
The real fun is when I made the realization that I was actually doing Test Driven Development to learn Perl. TDD is something I’ve always thought would benefit my coding style, but I never really realized how until today.
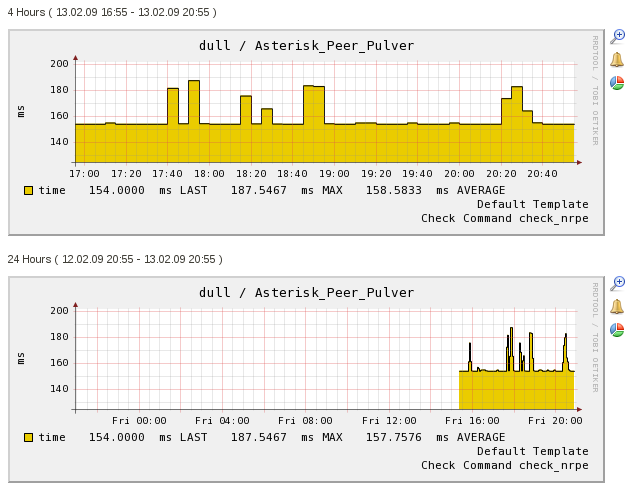
I’ve started helping out with a little bit of sysadmin at work, since our systems team is swamped most of the time. My task is to do an audit on our Nagios system and make sure everything is up to snuff. We’re running Nagios 3 on one machine and NRPE to pull performance data from the cluster (about 20 machines). NRPE is a plugin to execute scripts remotely to gather performance data.
Nagios can do both active and passive measurements, meaning it can execute scripts remotely, or sit and listen as your machines push data into it. We’re only using the remote execution method (via NRPE). One of the downsides to this is having to set up new machines with the scripts and plugins for Nagios. You have to set up both the script and config on the remote machine, and then configure the Nagios machine to know what scripts to run remotely. Even with all that, it does a good job, and seems fairly performant.
Graphs and more graphs
Nagios has some good graphs for reviewing performance data, and lots of options for configuring and customizing things based on your preferences. However, like many aging open-source projects, Nagios feels a little clunky, and it’s graphing system, while extendable (by the looks of things) isn’t quite as shiny as some of the newer systems I’ve looked at.
A typical Nagios graph looks like this (image from IT Slave):
The graphs are really good as they stand, you can zoom in to find out more detail on a set of measurements, and you can stack your measurements together for correlation, but it’s not very user-friendly, and requires nearly a sysadmin to accomplish.
Correlating data
One of the interesting things about having a lot of measurements, is finding fun and interesting ways to mash them together. I ran into Librato Metrics the other day while looking at some different options for graphing systems information in the cloud. I don’t want to replace Nagios, by any means, for what it does, it does really well.
What I want is a better way to correlate data.
Librato Metrics has an api available for several languages so you can post metrics information to their system on the fly. Compared to Datadog (which also looks very awesome, btw) who charges $15/host/month, Librato Metrics charges based on measurements, and they have a nifty little chart on their pricing page to give you an idea of the cost to use their service. According to that page, each measurement is going to cost you $0.000002 per measurement.
I did the math, for the ~180 measurements we run at work every 90 seconds, it would cost us about $12/month to use their service (compared to ~$300/month on Datadog for 20 hosts). The flip side to that is, Datadog has a whole bunch of 1-click integration scripts to get up and running, while Librato is still a bit of a WIP in that area. No skin to me.
So what do they offer?
Librato Metrics is really a data aggregation service, they offer the ability for you to create measurements with a namespace and a source, and then give you a myriad of ways to graph and correlate that data using instruments. Don’t just take it from me, go check out their video and see for yourself.
Some of the things that make this system fairly attractive is the use of Highcharts for the graphing, and a really slick theme that is nice to look at. Their dashboards are a fancy way to mash a whole bunch of instruments into one place.
A poor demo
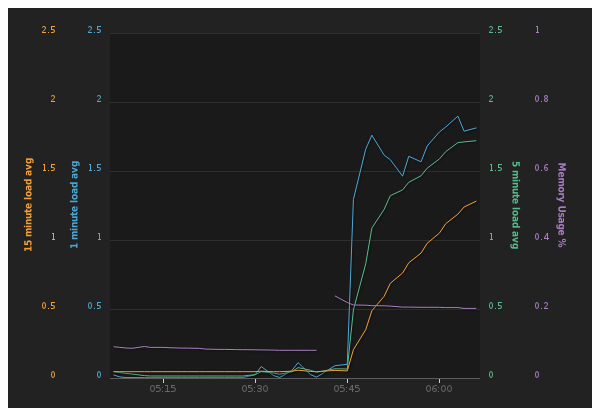
I’ve only had limited time to get started with the system, but I wrote a quick little demo script in node.js (of course) and tried it out on my EC2 instance.
For the demo I pushed load averages at 1, 5, and 15 minutes, as well as free memory on the machine (measured between 0.01 and 1.00).
Here’s the result:
To get the performance data, I just pulled down node-fibonacci and asked my EC2 machine to calculate the fibonacci sequence for to a ridiculous length (three million trillion or something)… needless to say, it stressed out the machine a bit…
It basically takes an OS measurement on CPU and calculates free memory every 90 seconds. Then it pushes that information to librato, and carries on. Since it’s node, the whole operation happens asynchronously and everybody’s happy.
HipChat
Did I mention they have 1-click “send this snapshot to HipChat“ also? That’s just fun.
Happy happy!
There you have it, fun fun. Can’t wait to start profiling some scripts and aggregating some other data with this thing.
If you’re not using SublimeText2, you really don’t know what you’re missing… Just head on over to the home page and see a few of the features that make this just a fantastic editor. I won’t go into detail just yet…
Snippets
What I wanted to write about today is snippets. The snippet system in SublimeText2 is quite… well… sublime. But I was originally having trouble getting them to work (or so I thought).
To start with, both selfs are highlighted, as per Sublime Text 2’s multi-select style. Sweet. Hit <tab> and we jump to method selected, fill that in, hit tab one more time, and now // content is the current selection, fill in to finish.
I’m a modern-day hack: I read a bit, books and online, I mash together chunks of code and frameworks to try and make things work (or break), I like to try things that few have attempted, with pretty decent success. For the longest time I didn’t feel entirely comfortable in my shoes as a “programmer”, meaning that I was writing code, my shit was working, but I felt I never met the generally-accepted criteria of a modern programmer. One of the things that kept me feeling unworthy was my lack of the use of teh “MVC” in my works.
Model-View-Controller
I’m not going to go too far into what MVC is, if you’re reading this, then you already have a good idea already. Besides, there are internets out there to tell you what it is. I’m here to talk about why you should be using it.
The problem with MVC is that it’s misunderstood.
Misunderstood for several reasons:
because I think the term itself has become a buzzword. To the layperson or aspiring programmer, the concept of MVC is just another term among a slew of catch phrases that one encounters trying to decode the mystery of developing for the web,
next, it seems every new framework that totes the label ‘MVC’ isn’t really a true representation of the pattern, or else it’s some derivation of MVC that still doesn’t really explain what it is.
last, MVC can be hard, or at least hard to pick up and understand. Let’s look at an example of that next.
Picking on someone…
Take the Actionscript framework Robotlegs, for example. There are several key components to setting up a project with that framework (have a look at their flow diagram):
Views
Mediators
Context
Commands
Actors
Services
Don’t get me wrong, Robotlegs is a great framework, but it’s no wonder people are confused! Before successfully getting a project off the ground with Robotlegs, I think it took me 2 or 3 attempts to get my head wrapped around the minimal requirements. I mean, in all of this, which one is the Model? Where’s the Controller? There isn’t even a ‘View’ class in Robotlegs.
It felt like pulling teeth to really ‘get it’.
If it’s so crazy, then why use it?
Lots of times when I read about MVC, I see lots of words like “clean code separation”, “visual flexibility”, “better workflow”, etc. I think everyone who has thought about MVC but isn’t using it yet needs that last little bit to really convince them:
MVC is about sanity.
Sanity because and MVC or similar (MVVM, MVCS, MV*) pattern helps you separate your application layers, which, without practice, is hard to do. But without regurgitating all the other buzz words and phrases to try and convince you it’s worth using, let’s make up a new idea about MVC:
Data state representation bindings.
Let me clarify that: bindings that automatically change the interface to represent the state of the data. This means (in the case of a browser or something similar) that when you click an item, you don’t reach in with your code and change the page or another element on the page, you change your data instead. And if you have your bindings set up properly (or your framework for that matter), then the view updates for you. With this kind of setup you can wire as many views to a single piece of data as you want, and in order to update them all, you only need change the state of the data, and they will all automatically update.
See? Sanity.
Time to grow up…
If you’re not using some MV -ish framework or some kind of bindings for your project, there will never be a better time than now. You owe yourself a little sanity, take the plunge. You’ll thank yourself in the end.
Note: Zombie.js has had several new releases since I wrote this post. I’ve caved in and tried it again, and the newer version of Zombie seems to be working out better than previous versions. Future post(s) to come.
Zombie.js
I’ve been waiting for quite a while to try out zombie.js. It seems like the “End All.” of hard-to-test-super-complex-setup systems, for instance, a system where you have a SSO with several redirects, then multi-panel single page app with a lot of ajax requests and dynamic resources. Unit tests are one thing, but I really wanted to test that the whole setup was going to perform as expected.
#epicfail
After a day and a half (and part of an evening), I think that zombie.js is probably trying to be a little too magical. On my Vagrant box (Ubuntu Precise server) I’m running Node v0.8.6. At first I tried the setup with Mocha as prescribed in the docs, but to no avail. The biggest problem: our SSO system does a couple redirects when you hit the application page, and just like another user expressed in this discussion, my .then() callback fires way too prematurely, and never hits the actual redirect. Specifying the wait time didn’t help any either.
Frustration at it’s finest
I’m not one to give up, I rarely let a hard problem get by me, but this isn’t just a ‘tricky’ API I think. I think it’s an immature project. Harsh, I know, but have a look at this example:
1 2 3 4 5 6 7
var zombie = require('zombie') , browser = new zombie.Browser ;
browser.load('<html />', function () { console.log('foo') });
Loads this HTML, processes events and calls the callback.
But it actually gives:
1 2 3 4 5 6 7 8 9 10 11
TypeError: Object #<Browser> has no method 'load' at repl:1:10 at REPLServer.self.eval (repl.js:111:21) at Interface.<anonymous> (repl.js:250:12) at Interface.EventEmitter.emit (events.js:88:17) at Interface._onLine (readline.js:199:10) at Interface._line (readline.js:517:8) at Interface._ttyWrite (readline.js:735:14) at ReadStream.onkeypress (readline.js:98:10) at ReadStream.EventEmitter.emit (events.js:115:20) at emitKey (readline.js:1057:12)
Am I just doing something plain wrong?
So the tally is…
Zombies 1, Aaron 0
As a side note, selenium is looking to do exactly what I want.
At my current position I’m getting the opportunity to do a lot of testing with selenium (which I’ll talk about later) and vagrant. One of the things that I need to accomplish during testing is dynamically starting the development environment in “TEST MODE” to perform functional testing against the webapp backend.
I started thinking it’s a permission issue or something, but, no, the vagrant user should be root, nothing seemed to make the simple command execution work, at least, I can’t think of another way to change directory on a linux box. And to make things more intersting, it didn’t seem to matter if I used PySFTP or the aforementioned ssh.py, the result was the same.
Turns out to be simple
I’m not exactly sure why, but this post on teh Stack led me to the solution, turns out it was simple:
1 2
>>> client.execute('cd ..; pwd') ['/home\n']
Just needed to execute the commands together. Why? Your guess is as good as mine…
How’s that for a title? I just have to say, git is pretty awesome, but I’m assuming you knew that. I read an article today where (for the first time I’ve seen) someone was making a case for bazaar over git. I used bazaar for our development team for almost two years, it was my “upgrade” to “distributed” over subversion. Sorry, can’t find the article. In a nutshell, 20 out of dvcs users [on that webpage] prefer git over bzr. Maybe corn flakes too…
tldr;
Click the little ‘X’ in the upper-right corner…
good, bad, indifferent
I’m not really going to argue points about the two systems today, all I’ll say is that I’m totally digging git. And my motivation is several-fold:
Video - Summary: Linus Torvalds tells Google staff how stupid they are ‘coz they don’t use git… over and over and over again.
Like, the internets use github, both of them, duhh
I get to use it at work :)
Further rationale
Bazaar was great, don’t get me wrong, but some of my newest most favorite features are (in no particular order):
On-the-fly branching! How cool is that?? In bzr (or svn) a branch would require a different folder. In-place branches are wicked.
Submodules Is there another system where this actually works?
There’s more, but that’s on the top of my list right now.
mixin(setuptools)
One of the neat things about settling in with a new development team is the things that I learn. At the top of my list are:
the things I’ve been doing right,
the things I’ve been doing wrong.
Of the latter, the first that comes to mind is setuptools. I’ve been managing Python dependencies manually for the last several years, in my mind, somehow, convinced that efficient dependency management in Python was somehow flawed, or “seldom agreed upon”. Probably a result of me being in a hurry most of the time.
Thankfully, I’ve seen the light! A colleague at work turned me back on to virtualenv, and I now realize what I’ve been missing in python all along: a reliable, simple deployment strategy. I’ll have to write more on that workflow later.
mixin(git)
This part is my favorite: without too much trouble, you can configure setuptools to pull from a github repo (or probably any other repo). There are only two criteria:
The trick in all this is the #egg=my_other_package-1.0.0 part, setuptools will recognize the package name and match it up with a required package in install_requires. It even has a pretty smart way to differentiate package versions.
wrapping up
Without too much trouble, a very efficient development/production workflow can be set up with the combination of virtualenv, git, and setuptools. It’s definitely an exciting time to be in software development.